SipHash 是一类针对短消息设计的伪随机函数族,相较于其他的哈希函数有在短消息上性能高、由于随机输入的存在难以构造哈希 dos 攻击的优点,是 rust 、python 的内置哈希函数实现。
实现
对于 SipHash-c-d 函数族,输入为一个 128 bit 的 k 和 可为空的输入 m,输出为一个 64 位长度的 SipHash-c-d(k,m)。其中 c 为 “compression rounds” 的次数, d 为 “finalization rounds” 的次数,“compression rounds” 和 “finalization rounds” 在之后中有说明具体的实现步骤。
初始化
首先使用 k0、k1 初始化四个值 v0 、v1 、v2 、v3,其中 k0、k1 为 输入 k 的 64 位的小端编码 (也就是两个 u64 值 k0 、k1 组成了 k )。
对于其中的常量,论文的选取解释为:
The initial state constant corresponds to the ASCII string “somepseudorandomlygeneratedbytes”, big-endian encoded.
论文中提出只需要满足 v0 和 v1 不同于 v2 和 v3 即可(也没分析为啥。。。)。
the only requirement was some asymmetry so that the initial v0 and v1 differ from v2 and v3.

Compression Round
在初始化状态后,将输入的字符串进行编码,将输入的字符串以每 8 字节作为一组以小端序编码成 64 位的数 ,最后不够的用 0 做填充,最后一个字节的值为输入的字符串长度 。具体来说,编码的过程如下图:
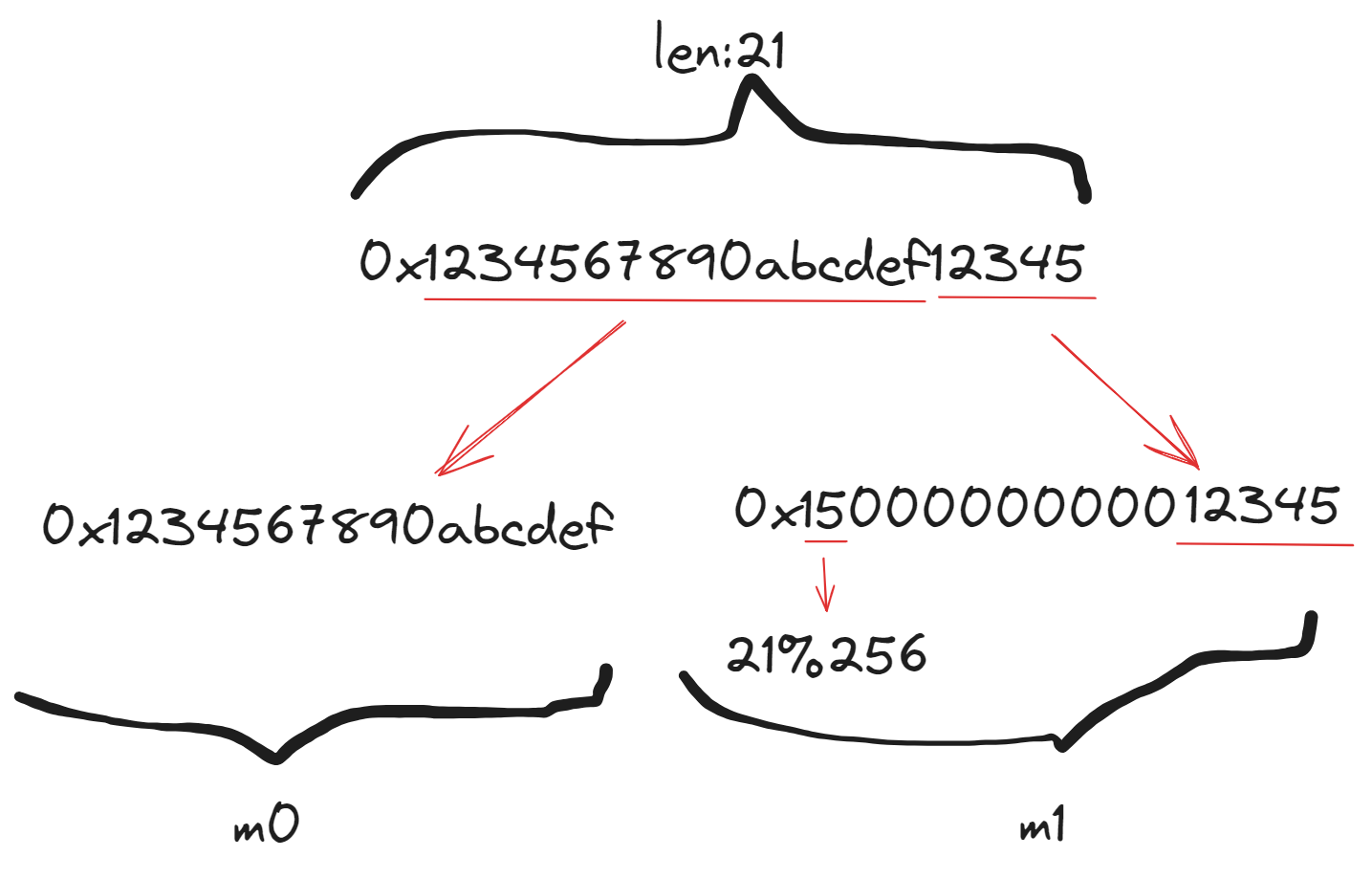
在将输入 s 编码成 后,对于每个 执行以下步骤,迭代执行完所有的输入后,Compression Round 完成。
PS: 巨💩🤡的是论文中的 “For example, the one-byte input string m = ab is parsed as m0 = 01000000000000ab”。开始我还以为输入的是字符串 “ab”,没看到 “one-byte input”,导致编码输入 m 这块卡了一会。感觉写成 “0xab” 和 “0x01000000000000ab” 会好一点🤡。
Finalization Round
在所有的输入字节处理在 Compression Round 处理完成后,将 和常量 (也是一个随机的非零值即可) 进行异或,再进行 d 轮 SipRound 之后,将 、、、 进行异或和后得到最终的 64 位哈希值。
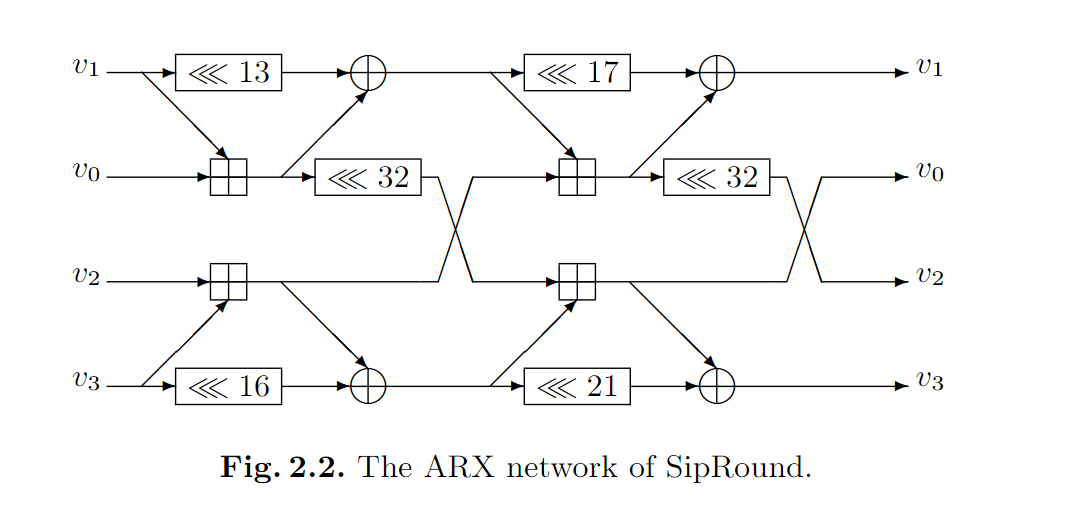
SipRound
SipRound 的运算过程如下:

安全性分析
#todo
- [ ] SipHash 安全性分析